MySQL隔离级别
数据库隔离级别有四种,由高到低分别是 Serializable(可串行), Repeatable Read(可重复读), Read Committed(读提交内容), Read Uncommitted(读未提交内容)。一般的数据库默认隔离级别为RC,而MySQL默认的隔离级别为RR。
数据表准备
我们在MySQL中新建了四个表。
对于test_1表,由id、name两个字段组成,其中id为主键。
对于test_2表,由id、name两个字段组成,其中id为主键,name为唯一索引。
对于test_3表,由id、name两个字段组成,没有索引。
对于test_4表,由id、name两个字段组成,其中id为主键,name为普通索引。
1 | create table test_1 ( |
在数据库隔离级别中,我们只用test_1表。在死锁学习中,我们才会用到其它表。
设置autocommit为False。
1 | set @@autocommit = 0; |
Read Uncommitted
数据库隔离级别设置1
2set @@global.tx_isolation = 'read-uncommitted'; #全局隔离级别
set @@tx_isolation = 'read-uncommitted'; #当前会话隔离级别
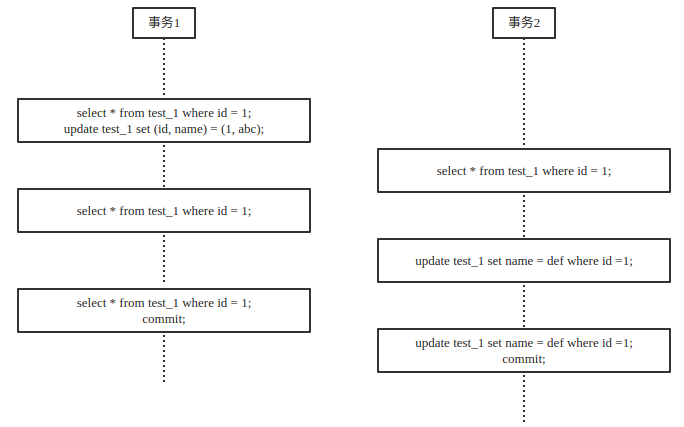
客户端事件(时间顺序)
执行结果
结果分析
事务1查询到id=1的数据为空,接着便插入了一条id为1的数据。此时事务1并未提交,而事务2读取id为1的数据,可以读到未提交的数据。
若事务1回滚,则事务2读到的数据就是一条不存在的数据,也就是脏数据,称之为脏读。
第四步事务1再次读取id=1的数据,这次在事务1未提交的情况下也能查询得到,是因为InnoDB在默认情况下会给insert语句上X锁(排他锁),而X锁对同一事务内的无锁select请求兼容。
第五步事务2写id=1的数据,此时由于事务1未提交,事务1中id=1的行锁未释放,导致事务2中的锁请求等待超时。
若占有锁的事务1提交了,锁随即被释放。未占有锁的事务2可以申请id=1的行锁了,数据被更新。
值得注意的是,RU的特点是读不申请锁。能够在其他事务未提交的情况下读取到未提交的数据,它的优点是能够最快的读取到有可能准确的数据,它的缺点是数据准确性不大,很有可能读到的这条数据不存在。
Read Committed
数据库隔离级别设置1
2set @@global.tx_isolation = 'read-committed'; #全局隔离级别
set @@tx_isolation = 'read-committed'; #当前会话隔离级别
客户端事件(时间顺序)
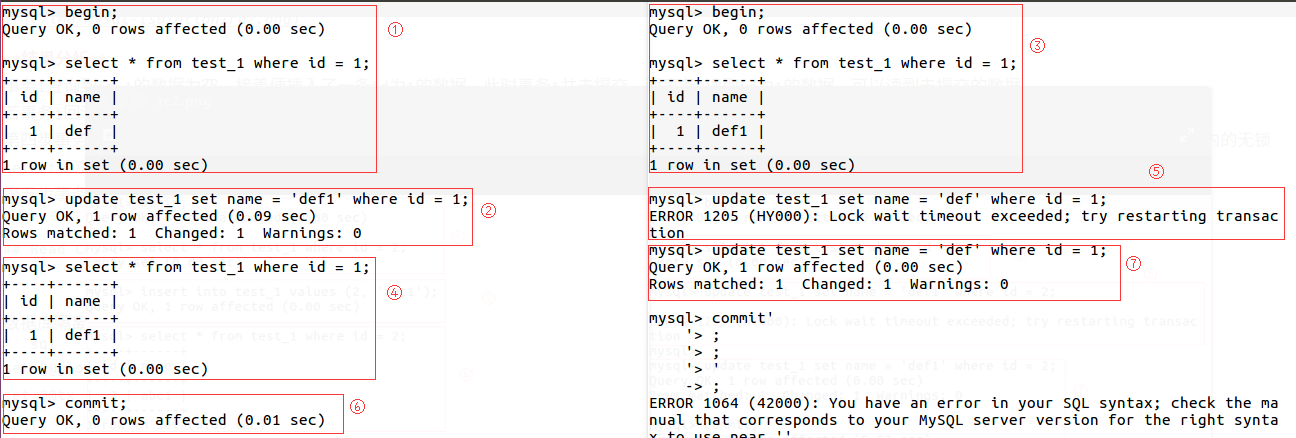
执行结果
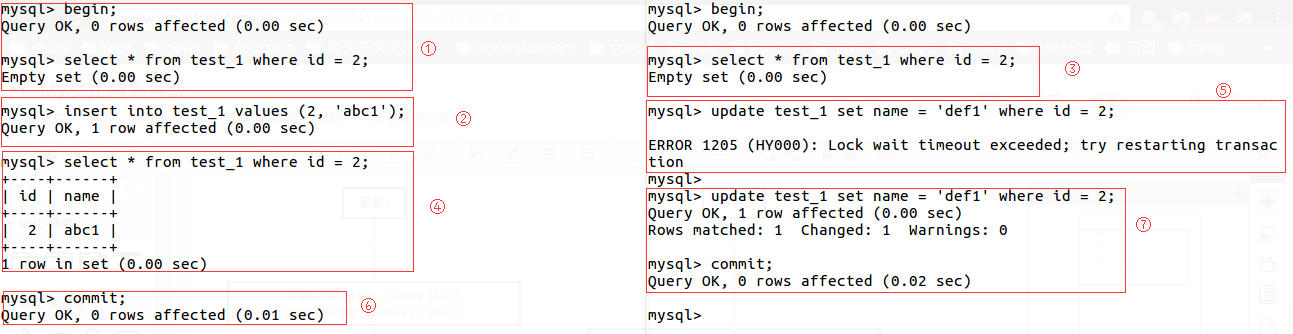
结果分析
事务1查询到id=2的数据为空,接着便插入了一条id=2的数据。此时事务1并未提交。
事务2读取id=2的数据,仍然为空。这是因为数据库隔离级别为Read-Committed,事务1未提交,事务2就读取事务1新添加的数据,此数据库隔离级别不允许脏读。
事务1能够读取到id=2的数据,因为在同一事务中,这是无锁的select请求。
事务2更新id=2的数据时失败,原因是事务1锁住了id=2的行数据。
事务1提交事务后,事务2进行更新id=2的数据时成功,原因是事务1提交后,占用的id=2的锁被释放了。事务2申请锁成功。
值得注意的是,RC的特点是事务与事务间的读操作隔离,事务1的读操作与事务2的读操作分离,直到某一事务提交后,其他事务又在这个时间点上进行事务隔离。它的优点是保证了不会脏读(读到不存在的数据),缺点是会出现同一事务两次读的结果不一致(如事务2),导致在这一事务内逻辑可能会错误。
Repeatable Read
数据库设置1
2set @@global.tx_isolation = 'repeatable-read';
set @@tx_isolation = 'repeatable-read';
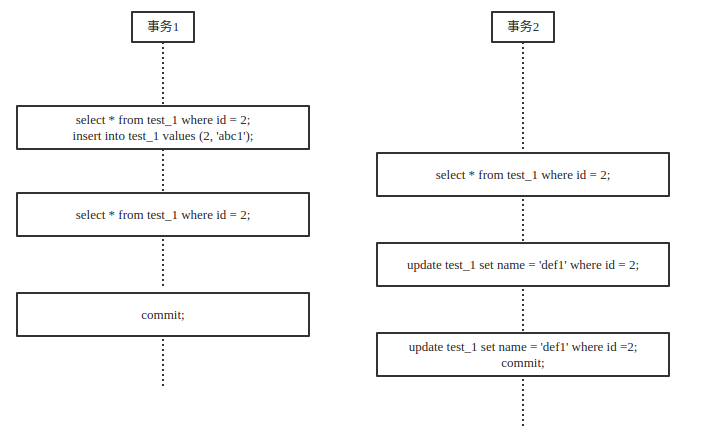
客户端事件(时间顺序)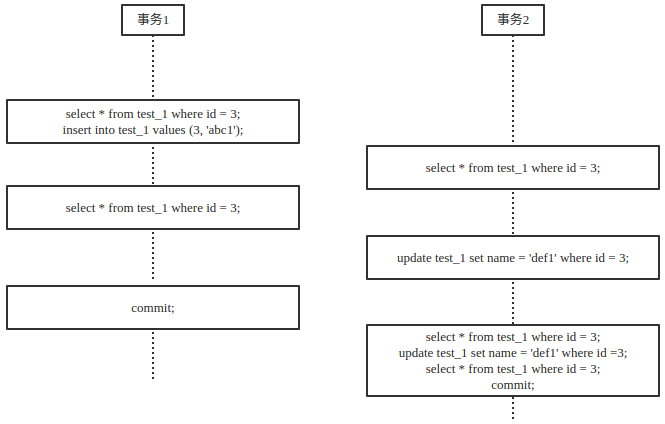
执行结果
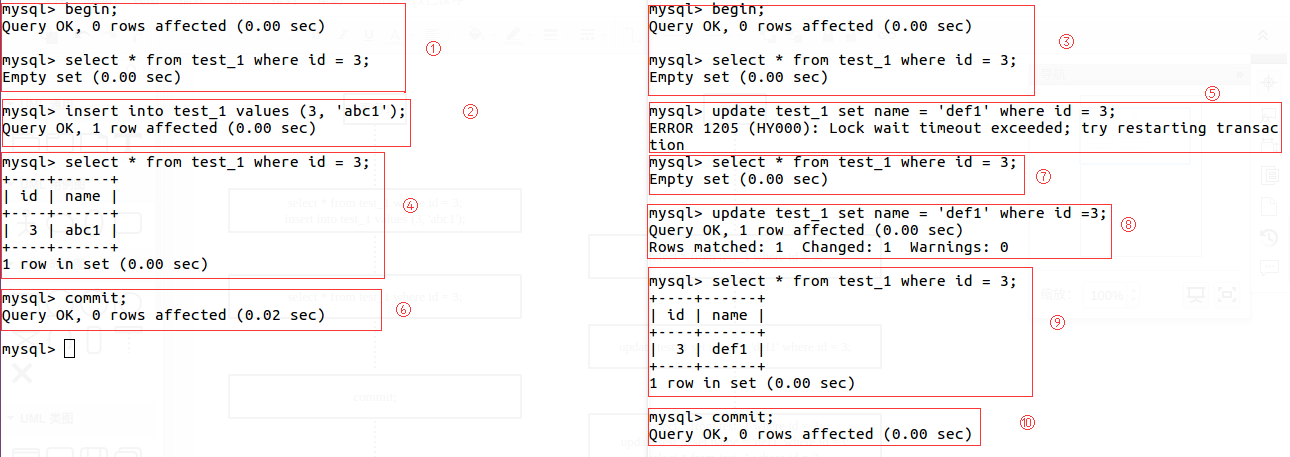
结果分析
事务1查询id=3的数据,结果为空。随后插入一条id=3的数据,成功。此时事务1申请并占有id=3的行锁。
事务2查询id=3的数据,结果为空。因为在RR隔离级别下,不会发生脏读,事务1修改数据未提交,事务2不可读取。
事务1查询id=3的数据,结果为事务1修改的数据。因为读同一事务下写操作修改过的行数据不会申请锁。
事务2更新id=3的数据,失败。原因是事务1占有锁未提交,锁未释放,事务2申请锁失败,排队等待。
事务1提交后,事务2查询id=3的数据,结果仍为空。因为在RR隔离级别下,同一事务多个读操作结果一致,保证了这个事务独立性(不被其他事务影响)。
事务2写id=3的数据,结果成功。因为事务1提交后释放id=3的行锁,事务2申请占用锁成功。
事务2读id=3的数据,结果读取到事务2刚刚更新到的数据。说明了可重复读可以保证多次读的结果唯一,除非在这个事务写成功后再执行读操作。这样才会影响读结果。
从执行结果来看,RR隔离级别可以防止在同一事务内读到不同的数据,它在读到的数据中加锁(记录锁),保证该事务内读到的数据相同。但若事务内对此条数据作了更新,则记录锁也随之更新。
RR隔离级别虽然能够防止不可重复读,但是并不能防止幻读(多次查询结果本应该不同,但结果相同)。
Serializable
数据库设置1
2set @@global.tx_isolation = 'serializable';
set @@tx_isolation = 'serializable';
客户端事件(时间顺序)
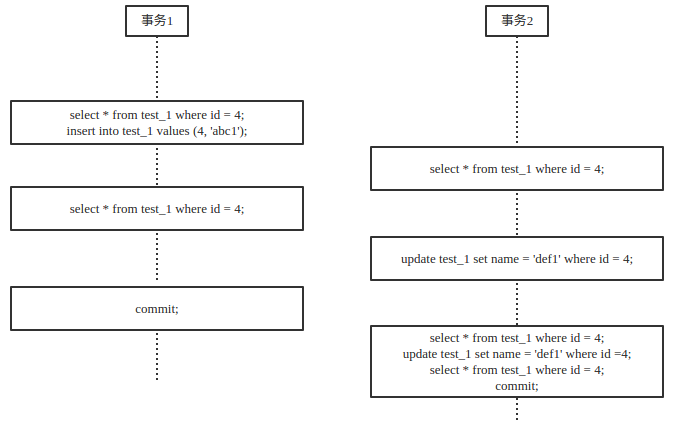
执行结果
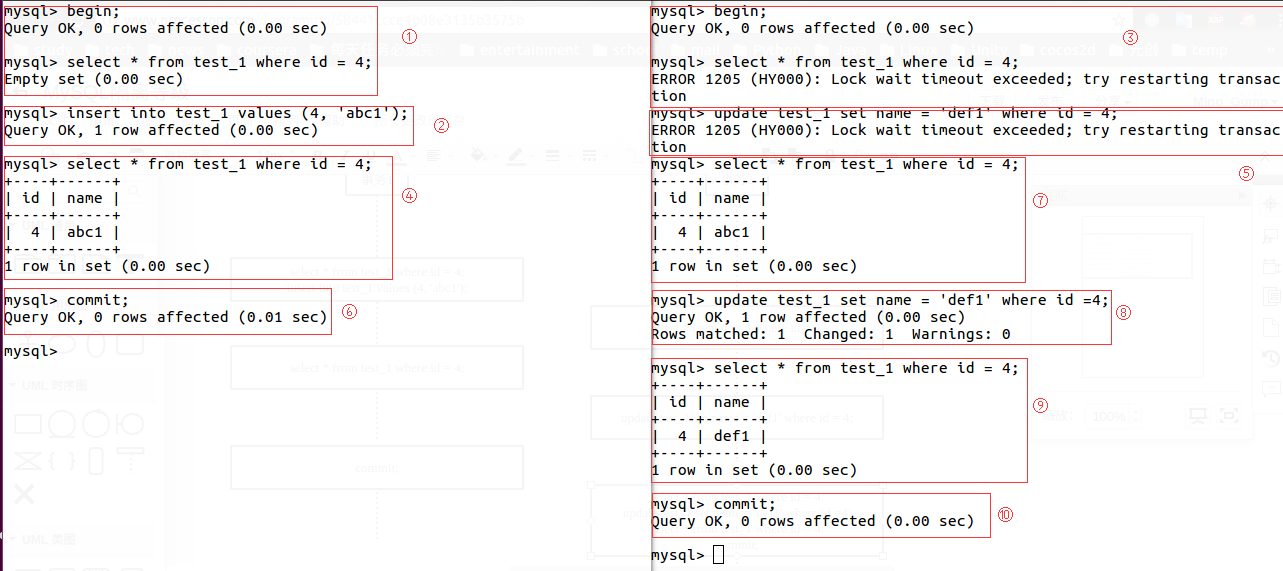
结果分析
事务1读id=4的数据,结果为空。随后插入一条id=4的数据,插入成功。
事务2读id=4的数据,等待超时。原因是在Serializable隔离等级下,读操作需要占用锁,而id=4的行锁被事务1占用了,因此读取失败。
事务1读id=4的数据,读取成功。因为在同一事务下,读取写过的行数据不需要占用锁。
事务2写id=4的数据,等待超市。原因是在Serializable隔离等级下,写操作同样需要占用锁,而id=4的行锁被事务1占用了,因此读取失败。
事务1提交后,事务2读id=4的数据成功,写id=4的数据成功。因为事务1提交后,占有id=4的行锁被释放,事务2得以占用成功。
上面的执行结果分析出Serializable的隔离级别要求读写均请求锁。这样保证了数据库事务串行执行,优点是能够防止脏读、不可重复读、幻读现象,但缺点也非常明显,串行执行事务与单线程相似,效率低、资源利用率低,在多事务同时到达数据库时往往会造成等待超时的现象。
总结
数据库的隔离等级分四种,由低到高分别是Read Uncommitted(读未提交)、Read Committed(读提交)、Repeatable Read(可重复读)和Serializable(可串行)。通常我们需要根据实际情况选择数据库隔离级别,这样不仅可以优化数据库对业务的支持,也可以降低死锁发生率。那今天就写到这里先吧~