Python性能分析与优化(二) —— 优化每一个细节
这一篇博客写的是Python性能分析与优化第四章的内容,讲述的是如何优化Python程序。这里涉及到一些Python数据结构的性能问题,以及一些常用的Python优化技巧。我以前也写过一些Python程序,但是因为没有关注性能这一块内容,导致程序运行缓慢。现在开始,我更关注如何优化Python程序,使得我的程序更优美!
函数返回值缓存和函数查询表
顾名思义,函数返回值缓存和函数查询表就是利用空间换时间的策略,将程序运行时间大大缩短。三角函数的实现就是用到了函数返回值的缓存,利用空间换时间的策略达到快速返回三角函数值的效果。
1 | class Memoized: |
该函数的运行结果如下图所示:

当然了,上面的缓存用的是字典的键,根据实际情况,还可以用列表、链表、树做查询表。
从上面的结果看出,用固定参数+缓存数据的效果是最佳的,因为缓存数据就相当于第二次调用参数申明的数据,重复调用后,可以通过key-value的方法快速查找到对于的value,而随机参数+缓存数据的结果与其他两个结果是相差不大的,说明缓存的数据因为随机参数的原因没有调用到原来的key-value对,而是再次添加了随机的key-value对,增加了计算时间。
对于内存足够的机器(尤其是服务器),查询表的作用可见一斑。
使用默认参数
许多编程语言都会具有默认参数的定义,在python中,默认参数作为优化技术的一种,使用得并不十分普遍。
默认参数是直接优化Python解释器的工作方式,它可以在函数创建时就确定输入值,而不用在运行阶段才确定输入。
下面是默认参数的代码:
1 | # original function |
对应的输出结果如下图所示:

利用解释器的原理,在函数创建时就确定输入值,固然可以提高程序运行速度。但是这也破坏了程序的可读性,我认为这个优化方法并不一定可取。
使用列表表达式
python语言中有列表这一数据结构,它同时也包含了列表表达式的语法,比如”[x for x in range(100)]”。在python中,我们应该多用列表表达式来创建列表,而不是用循环的方式。这是因为使用列表表达式所花费的指令数量比for循环的指令数量要少。
1 | def loop(): |
结果如下图所示:
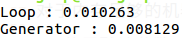
从上面的结果看出列表表达式的效率更高,但是在列表过大时,列表表达式可能就不太好使了。因为列表表达式需要直接产生每一个值,因此如果你要处理一个包含10万个元素的列表时,你可以用生成器表达式,不需要直接返回列表,而是返回一个生成器对象。当你请求列表元素是,生成器表达式就会为你动态的生成列表元素。
生成器就像这样“(2+x for x in range 100)”。生成器无法使用方括号来读写数据,只能通过遍历生成器对象获得列表,如“for number in my_list: print number”
其他优化技巧
尽量使用join函数链接字符串,而不是用+=操作符,因为这样做不仅消耗的时间更短,而且占用的内存也更少
有时不定义函数更好,因为调用函数会增加大量的资源消耗,而因此在不需要更改的模块(固定的模块)可以使用一个函数完成,而不要嵌套多个函数完成。虽然这样会破坏可读性,但是对程序来说会比较高效。
灵活使用数据结构,尽量用python标准库内的核心组件,因为他们都是经过优化的C语言写成的,因此效率更佳。