Python性能分析与优化(一) —— 性能分析器
今天读了Python性能分析与优化这本书大半了,开始写几篇博客,首先介绍一下这本书吧。Fernando Doglio写的这本书包含8个章节,其中第二章性能分析器介绍了几种关于Python性能分析的工具;第三章可视化分析数据介绍了几种GUI的性能分析工具;第四章优化细节介绍了一些优化性能的技巧。今天先从第二章开始吧。
cProfile
Python呢,自带了一个cProfile的包,它是用于测量CPU时间、统计函数调用次数的一个包。所以cProfile不需要安装,只需要在程序中导入cProfile的包即可。
首先我们来简单测试一下cProfile包的使用效果:
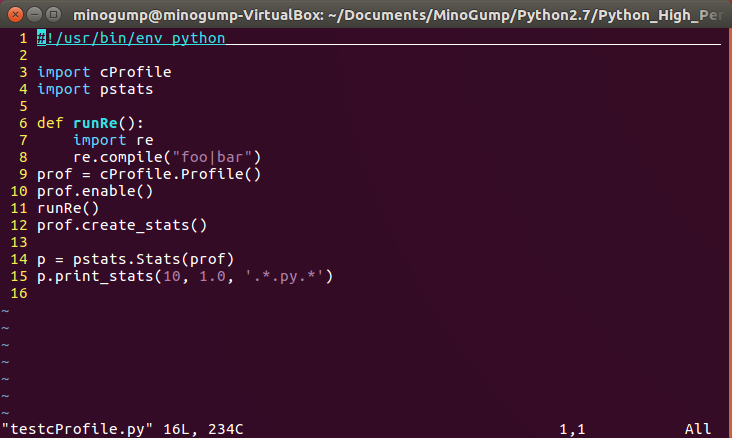
上面是一段简单的测试代码,其中我们创建了一个Profile类用于记录性能情况,用Stats类输出统计数据。这个print_stats函数接收了三个参数,第一个10表示打印前10行,第二个1.0表示按总行数的100%打印,第三个是正则表达式,用于匹配stdname。
对应的输出情况如下图所示:
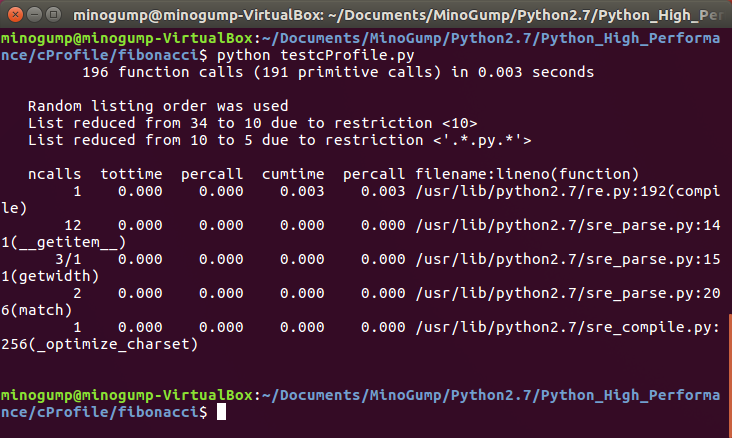
其中第一行告诉我们一共有196个函数调用被监控,其中191个是原生调用,表明这些调用不涉及递归。
ncalls表示函数调用的次数。如果在这一列中有两个数值,则表明有递归调用,第二个数值是原生调用的次数,第一个数值是总调用次数。如果第一个数值很大则表明需要进行内联函数扩展。
tottime表示函数内部消耗的总时间,这个性能信息可以帮助我们找到需要优化的点。
percall是tottime/ncalls的结果,表示一个函数每次调用的平均消耗时间。
cumtime是之前所有子函数消耗时间的累积和。这个数值可以帮助开发者从整体视角识别性能问题,比如算法选择错误。
另一个percall是用cumtime除以原生调用的数量,表示到该函数调用时,每个原生调用的平均消耗时间。
斐波那契数列性能
好了让我们实战一下cProfile性能分析器吧。这次我们选择用斐波那契数列生成函数进行示范。
首先是递归实现斐波那契数列的核心代码:
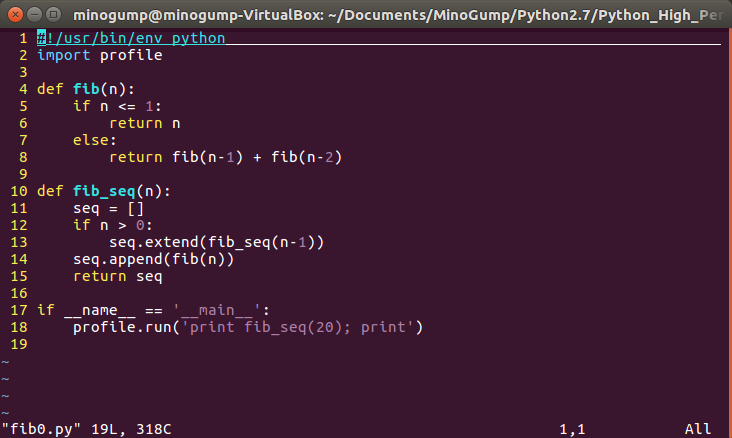
以及主函数:
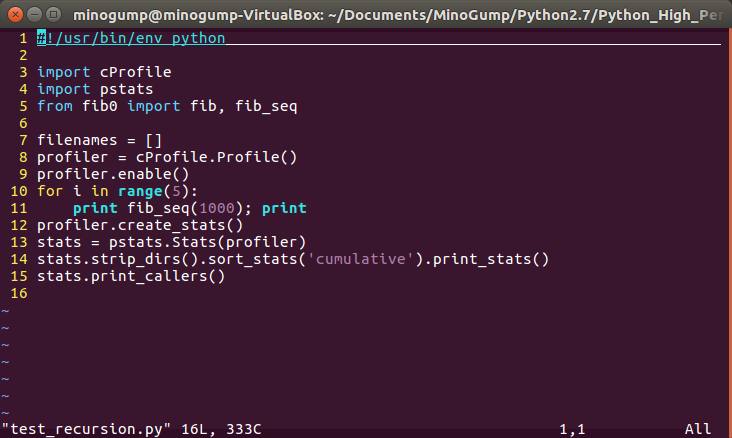
用python执行脚本结果如下:
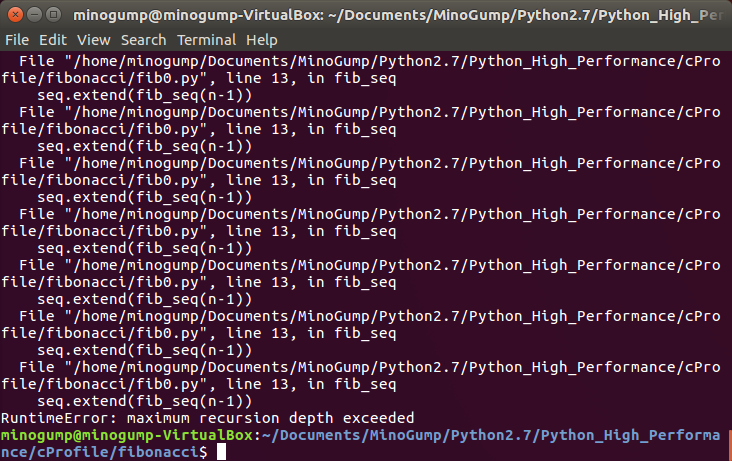
其实这是因为递归执行fib函数次数太多了,导致栈空间不足,因此我们修改一下程序,非递归执行(即采用迭代的方法获取斐波那契数列),得到新的版本如下:
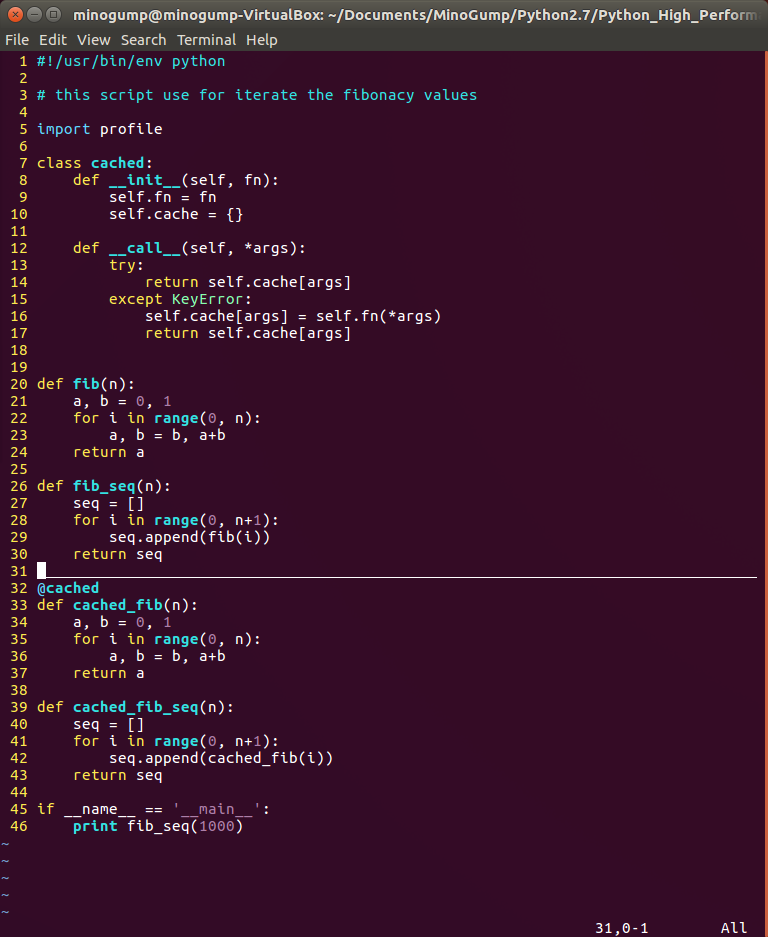
采用迭代的方法执行python程序,性能上是怎样呢?
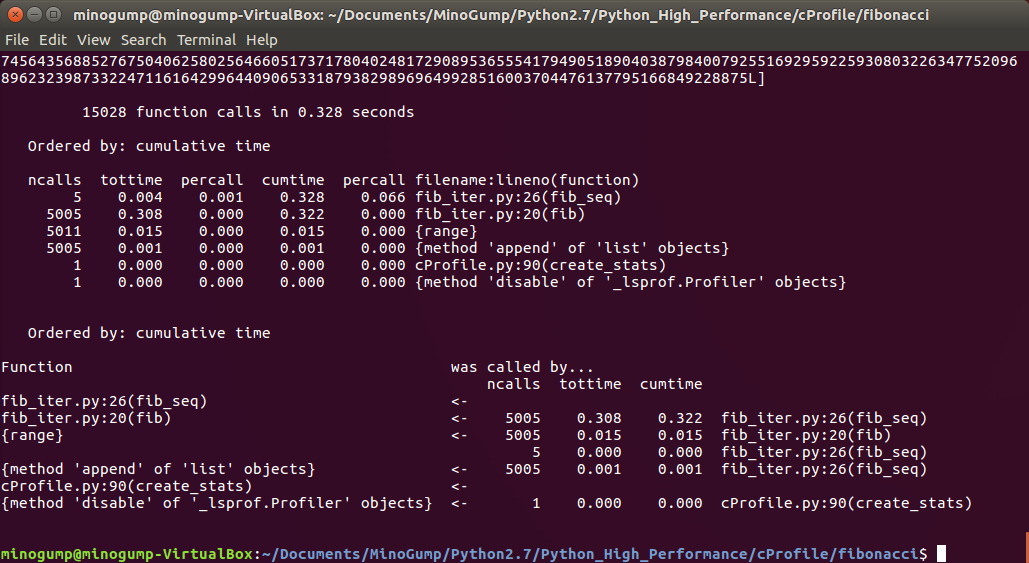
我们可以看到,fib这个函数被调用了5005次,占用的时间最多,达到了0.308s,还有0.015s用在了fib函数中的循环中,我们知道,因为在求斐波那契数列时,fib(1)是重复多次被调用的,于是我们可以使用缓存的方式来存储我们求过的斐波那契数据。代码如下:
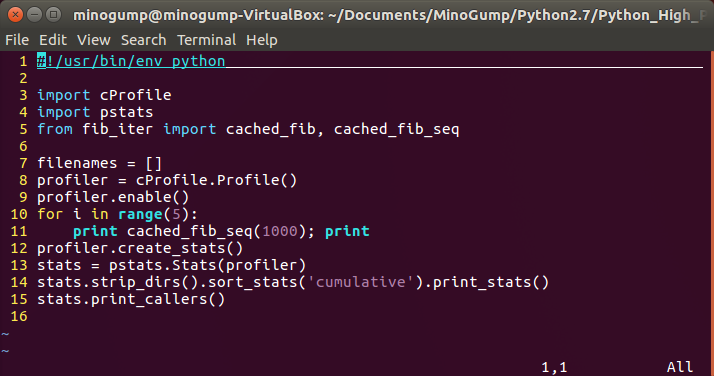
运行一下,看下结果如何:
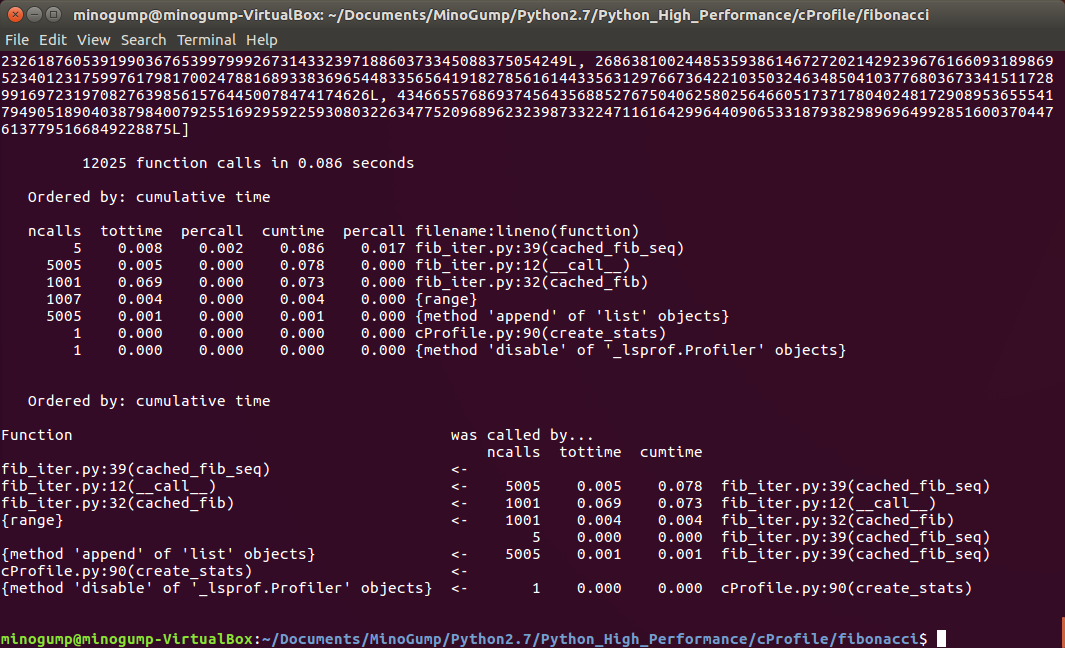
这下我们看到了,cached_fib函数只被调用了1001次,占用0.069s,也就是说,节省了4004次重新计算斐波那契数据。
总结
cProfile作为python自带的性能分析器,其优点是简单方便,能看到CPU的时间占用情况以及函数调用情况。有丰富的API用于执行、输出等。
但是其缺点是无法统计内存等情况,并且误差存在且不可忽视,因为cProfile统计时间利用的是系统内部的时钟,由于切换函数等,存在一定的滞后,所以误差不可避免。
line_profiler
接下来是一款逐行分析的性能分析器——line_profiler。它试图弥补cProfile和类似性能分析器的不足。其他性能分析器主要关注函数调用消耗的CPU时间。大多数情况下,这足以发现问题,消除瓶颈。但是,如果瓶颈问题出现在函数中的某一行,这是就需要line_profiler了。
安装
使用pip安装line_profiler:
1 | pip install line_profiler |
如果安装过程中出现问题,比如文件缺失,则可以安装如下依赖
2
>
斐波那契数列性能
下面用原来的代码继续分析斐波那契数列生成函数。这里的代码只需要更改一小部分的接口即可,其他的核心函数不用变。
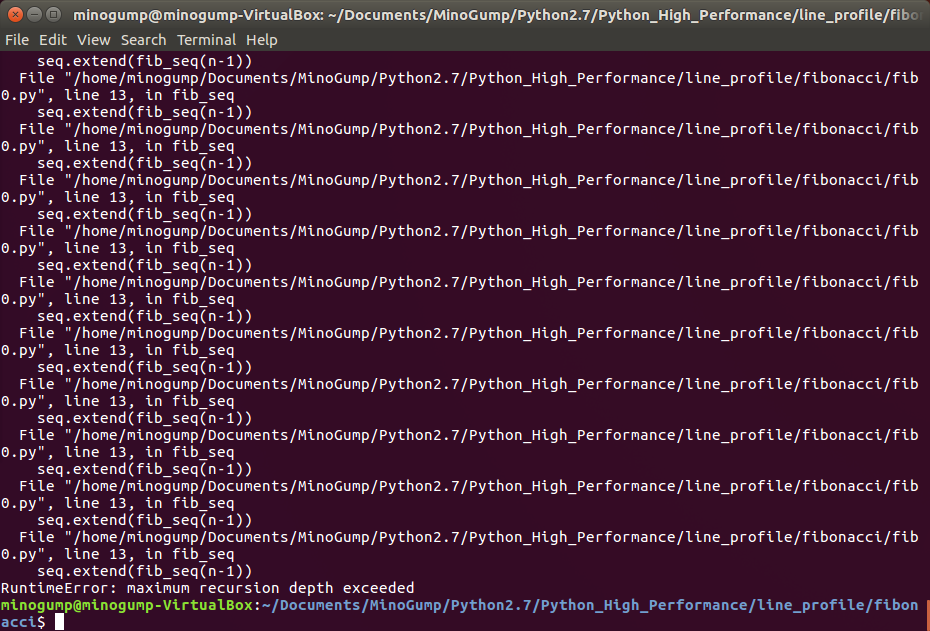
其结果如下,依然是递归调用次数过多,栈空间不足导致程序崩溃。
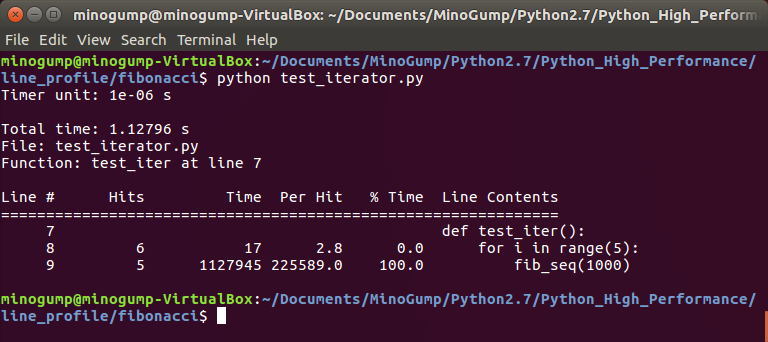
当我们将其改为非递归(迭代执行)时,分析程序每一行的性能:
小结
相比cProfile,line_profiler能够分析到每个函数的每一行的执行次数及时间等,但是缺点也很明显,line_profiler不能够从整体程序上进行分析,并且也没有针对内存等关键性能进行分析。所以line_profiler适合用于模块性能的分析。